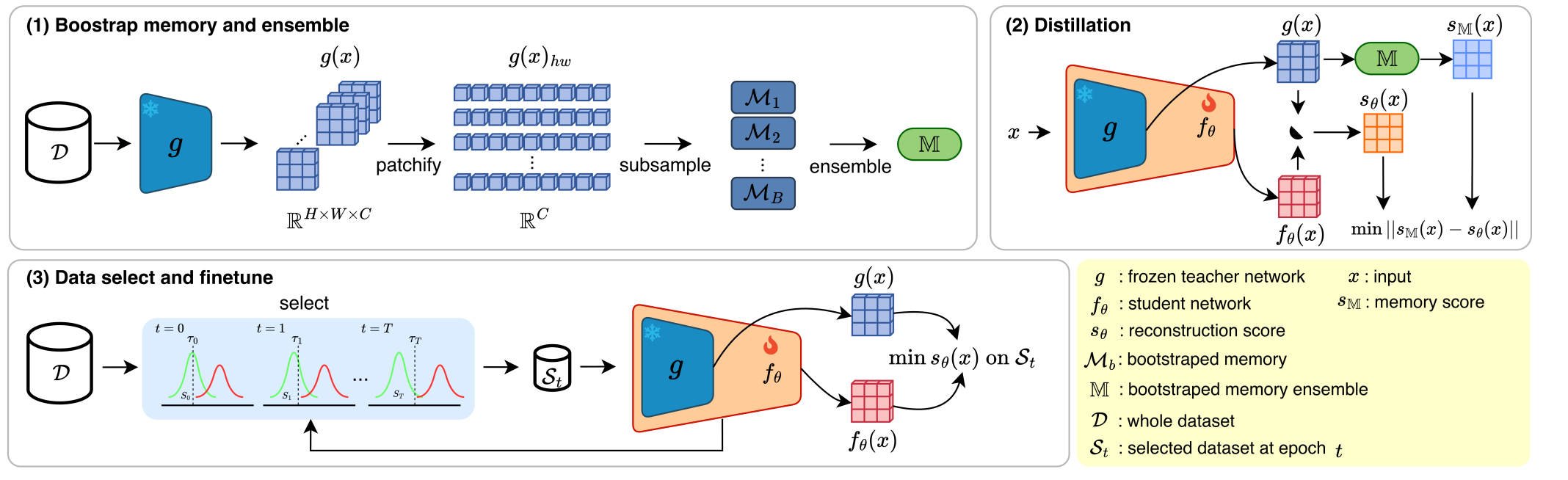
How MeDS works
MeDS reaches that robustness with a three-step recipe: (1) get a rough but noise-resistant read on which samples look suspicious, (2) sharpen that signal by distilling it into a small trained network, and (3) repeatedly retrain on the cleanest samples it can find — progressively earning precise, pixel-level defect localization. The three steps are detailed below.
Step 1: Memory Score Construction

The idea. A memory bank stores little snapshots (patch features) of the training images. To score a new patch, we measure how far it is from its nearest neighbor in the memory — far away means “unfamiliar,” which usually means a defect. The catch under noisy data: if defective patches sneak into the memory, defects start to look normal and the detector is fooled.
Our fix. Instead of one big memory, we build an ensemble of \(B\) small memories, each from a different random \(10\%\) subsample of the features, and average their scores. Because each memory is sparse, it only reliably captures the patterns that show up often — the normal ones — and “blurs out” rare defect patterns. In short, sparse subsampling acts like a low-pass filter: defects end up far from every memory and stand out, whether contamination is light or heavy.
\[
S_{\mathbb{M}}(x) \;=\; \frac{1}{B} \sum_{b=1}^{B} s_{\mathcal{M}_b}(x)
\]
Why there is a sweet spot. Make the memory too large and defects leak in and look normal; too small and even ordinary patches look unfamiliar. Theorem 1 makes this precise.
Theorem 1. Under a regularity condition, for any anomaly and normal patch features \(q_{\text{anom}}\) and \(q_{\text{norm}}\), the expected gap
\[ \Delta(m) \;:=\; \mathbb{E}\!\left[D(q_{\text{anom}}, \mathcal{M})\right] - \mathbb{E}\!\left[D(q_{\text{norm}}, \mathcal{M})\right] \]
satisfies \(\Delta(m) > 0\), and is decomposed into a second-order Taylor approximation \(\Delta_0\) with remainder \(\epsilon_0(m)\),
\[ \Delta(m) \;=\; \Delta_0(m) + \epsilon_0(m), \qquad \Delta_0(m) \;=\; \int_0^{\infty} \delta(r)\,\omega(m, r)\, \mathrm{d}r, \]
where \(\delta\) is non-negative and the weight function \(\omega(m, r)\) is unimodal with respect to \(m\). The expectation \(\mathbb{E}\) is taken over the memory \(\mathcal{M}\) randomly subsampled from the extracted feature set \(g(\mathcal{D})\) under the constraint \(\lvert \mathcal{M} \rvert = m\).
In words: the normal–anomaly gap \(\Delta(m)\) is always positive, and because the weight \(\omega\) is unimodal in \(m\), it is maximized at a moderate memory size. So there is an appropriate subsampling ratio that drives normal and abnormal features as far apart as possible.
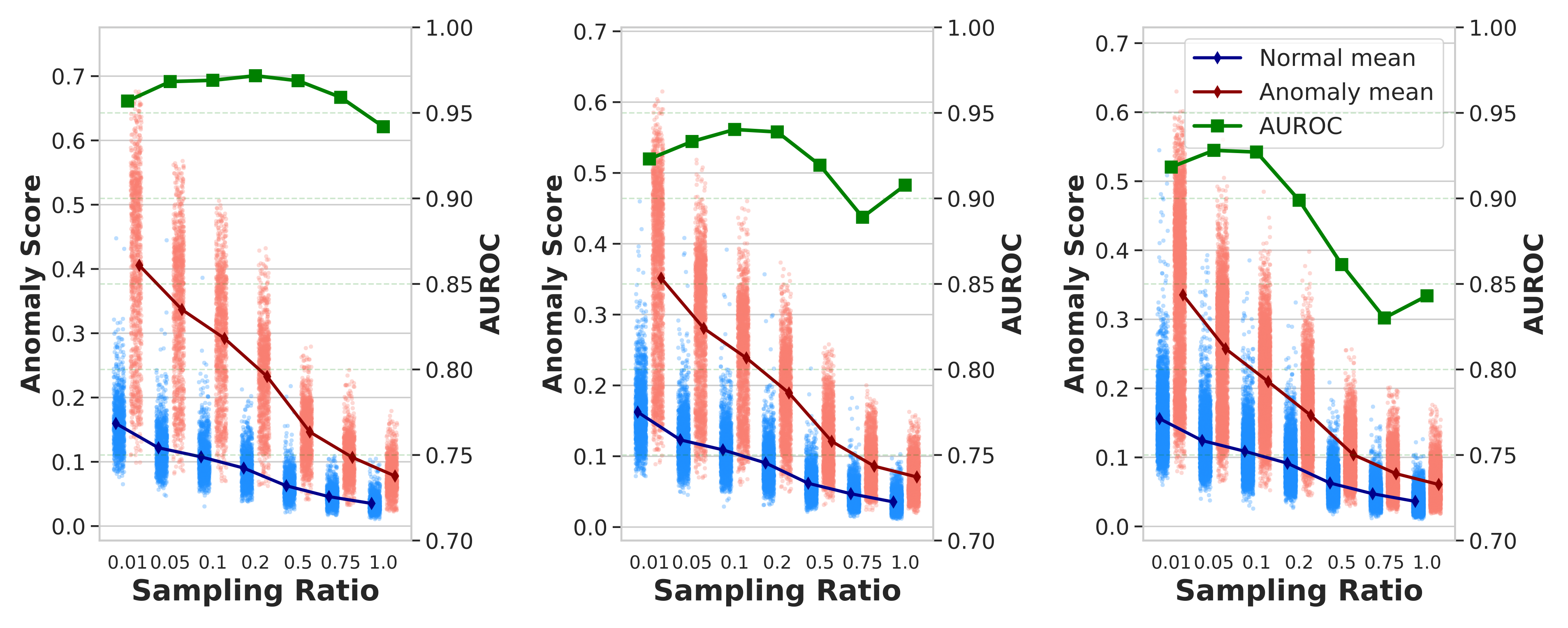
Theorem 1 in practice (at \(10\%/20\%/40\%\) noise): the gap between normal (blue) and anomaly (red) scores — and the resulting AUROC (green) — peaks at a small-to-moderate subsampling ratio, exactly the predicted sweet spot.
One limitation: these features come from a frozen, general-purpose encoder, so this read is only coarse — good enough to flag which images are contaminated, but not yet precise enough to outline a defect pixel by pixel. Steps 2 and 3 fix that.
Step 2: Distillation
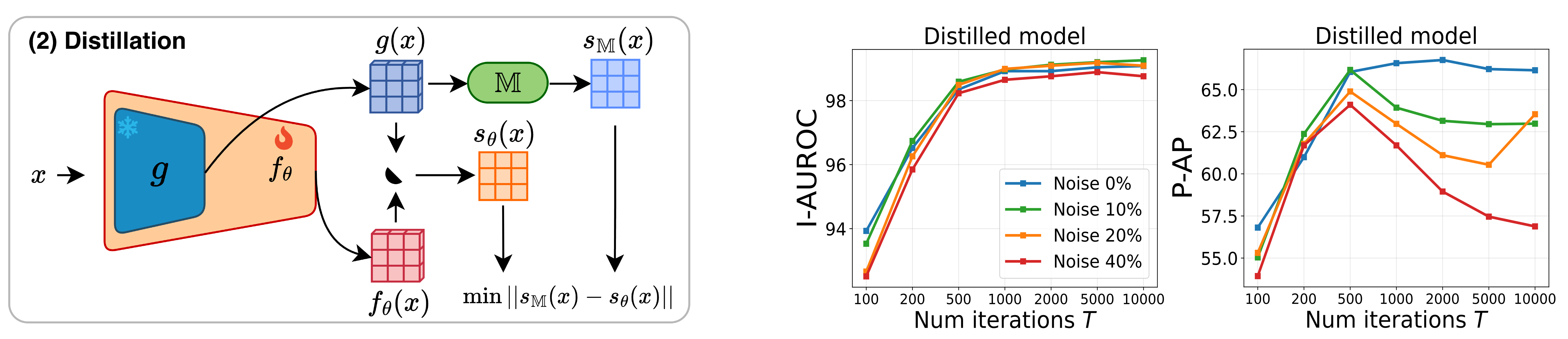
The idea. The Step 1 scores are robust but coarse, because they rely on a frozen encoder. So we train a small student network (a reconstruction model \(s_\theta\)) to reproduce the memory scores — but now learning directly from the factory images, so it picks up domain-specific detail the frozen encoder missed and amplifies the gap between normal and defective patches.
Why it doesn’t just memorize the defects too. This is where the early-learning bias (see Preliminaries) pays off: the student fits the majority — normal — patterns first, so it lowers their scores earlier and more than the rare defective ones, effectively denoising the memory signal for free.
The catch. Train too long and the network eventually memorizes the defects as well, hurting fine pixel-level accuracy; stop too early and it is under-trained for precise localization (see the graph on the right). Distillation alone can’t have it both ways — which is exactly what Step 3 resolves.
Step 3: Progressive Data Selection & Fine-tuning
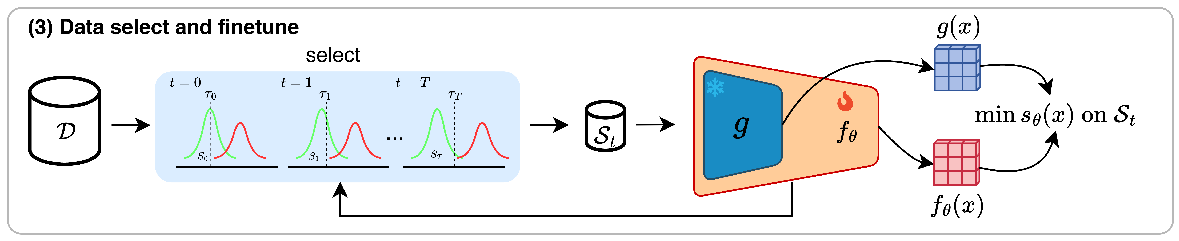
The idea. Use the Step 2 model to pick out the cleanest-looking images and fine-tune only on those. This lets the model keep training — getting sharper at outlining defects — without ever overfitting to the contaminated samples. We alternate (select → train), fine-tuning \(s_\theta\) on the progressively selected clean subset \(\mathcal{S}_t\):
\[
\min_{\theta}\; \frac{1}{|\mathcal{S}_t|} \sum_{x \in \mathcal{S}_t} s_\theta(x)
\]
Selection that self-corrects. A sample is kept when its score \(\eta_t(x)\) falls below a threshold \(\tau_t\). Early on, selection trusts the original distilled model and keeps only clearly-normal samples; as training improves, it leans on the current model and admits more samples — a positive feedback loop where a better model yields a cleaner subset, which in turn yields a better model.
\[
\eta_t(x) \;=\; (1 - \alpha_t)\, \max_{h, w} s_{\theta_0}(x)_{hw} \;+\; \alpha_t\, \max_{h, w} s_{\theta}(x)_{hw}, \qquad \alpha_t = \min\!\left(1,\; \tfrac{2t}{T}\right)
\]
\[
\tau_t \;=\; \operatorname{Median}\!\left(\eta_t(x)\right) + k_t \cdot \operatorname{MAD}\!\left(\eta_t(x)\right), \qquad k_t = k\!\left(\tfrac{t}{T}\right)
\]
Here \(\max_{h,w} s(x)_{hw}\) is the image-level score, \(s_{\theta_0}\) is the fixed initial (distilled) model and \(s_\theta\) the current one, \(\alpha_t\) gradually shifts trust from the initial to the current model over the \(T\) iterations, and the threshold \(\tau_t\) — built from the robust median and \(\operatorname{MAD}\) (median absolute deviation) — loosens as \(k_t\) grows. The payoff: precise pixel-level localization that stays robust at any contamination level, with no noise-specific tuning.
Results
We evaluate MeDS on three industrial benchmarks — MVTecAD, VisA, and Real-IAD — under contamination, following each dataset’s noisy-data protocol (MVTecAD at \(10/20/40\%\) noise, VisA at \(2/5/10\%\), plus the clean \(0\%\) case, and the official noisy setting for Real-IAD). The takeaway: where prior methods degrade as contamination rises, MeDS holds its accuracy — reaching 99.16% image-level AUROC on MVTecAD even at 40% noise — and sets state-of-the-art on VisA and Real-IAD under noise. It also works as a plug-in: dropped on top of existing detectors (HVQ, Dinomaly, INP-Former), it boosts their noise robustness with almost no cost on clean data.
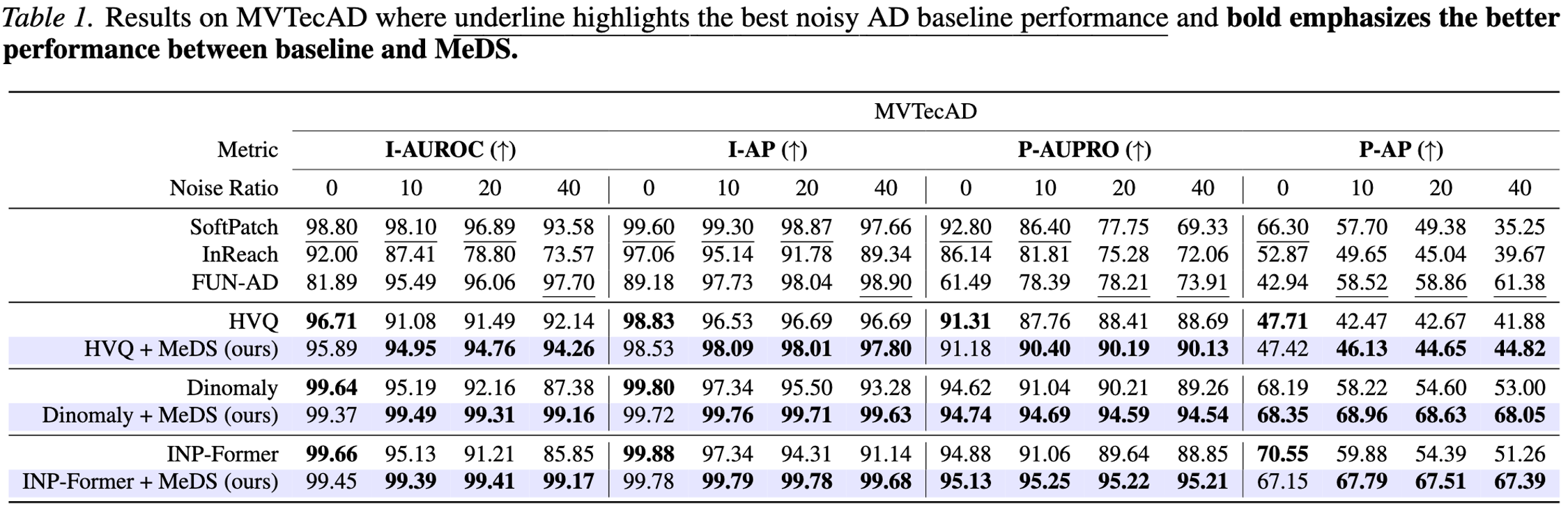
Table 1 — MVTecAD. Image-level (I-AUROC, I-AP) and pixel-level (P-AUPRO, P-AP) scores at \(0\!-\!40\%\) noise. The top rows are dedicated noise-robust detectors (SoftPatch, InReach, FUN-AD); below, MeDS is added on top of three modern backbones (HVQ, Dinomaly, INP-Former), and bold marks the winner of each baseline-vs-MeDS pair. Adding MeDS improves every backbone under noise — at only marginal cost on clean (\(0\%\)) data — and the gap widens as contamination rises: Dinomaly’s image-level AUROC falls to \(87.4\%\) at \(40\%\) noise, while Dinomaly + MeDS holds 99.16%, with the biggest gains on the hardest pixel-level metric (P-AP).
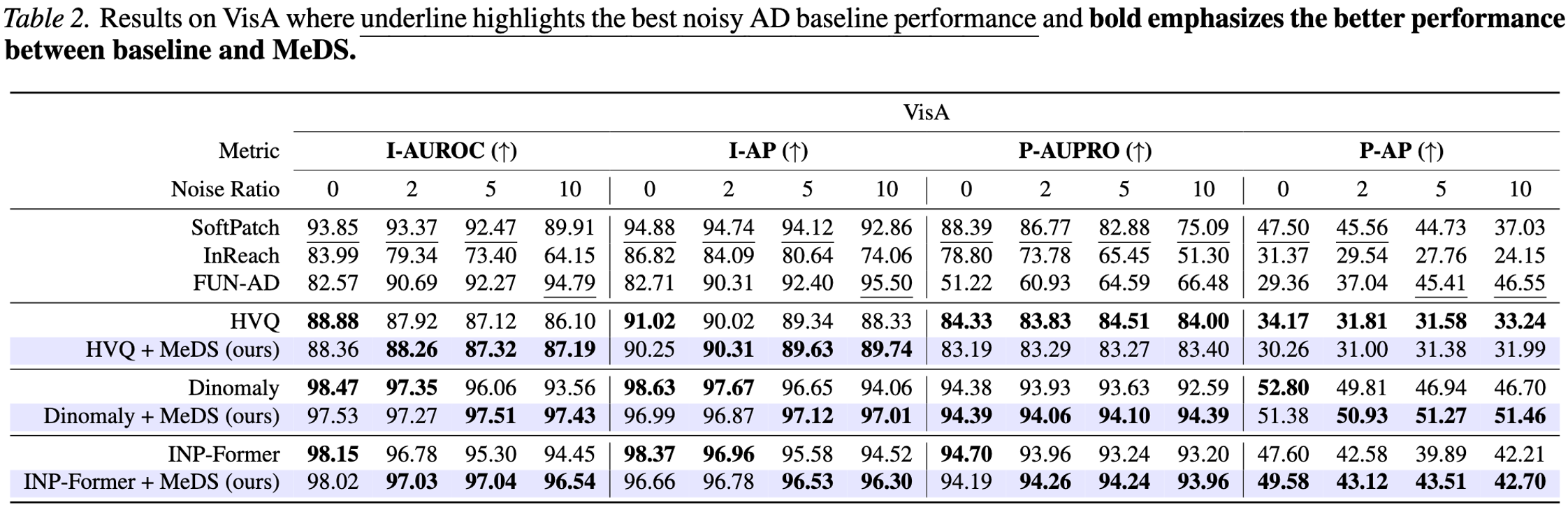
Table 2 — VisA. The same comparison at VisA’s noise ratios (\(0/2/5/10\%\)). MeDS once more lifts all three backbones on both image- and pixel-level metrics, with the largest improvements at the highest contamination — reproducing the MVTecAD trend on a second dataset.
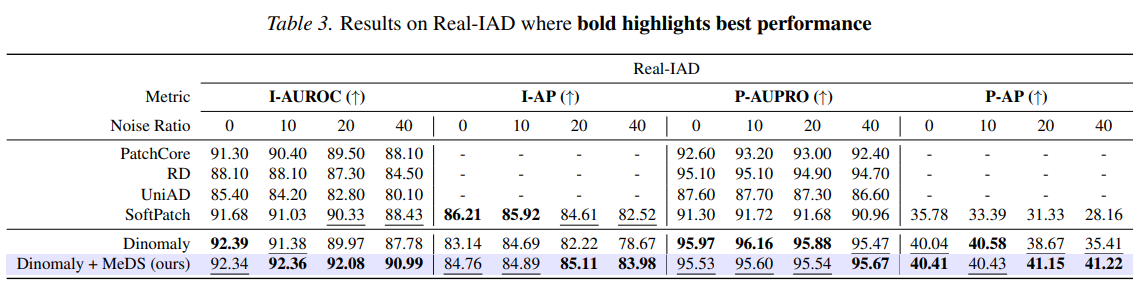
Table 3 — Real-IAD. Evaluated under Real-IAD’s official single-class noisy protocol (a separate model per category, which baselines such as SoftPatch require to scale to its many categories). Dashes mark metrics a baseline does not report (some methods report only a subset of the four image-/pixel-level metrics). Dinomaly + MeDS achieves the best overall balance across image and pixel metrics, and its margin grows with noise — e.g. image-level AUROC of 90.99% vs. \(87.78\%\) for Dinomaly at \(40\%\) noise.
Ablation & Hyperparameter Analysis
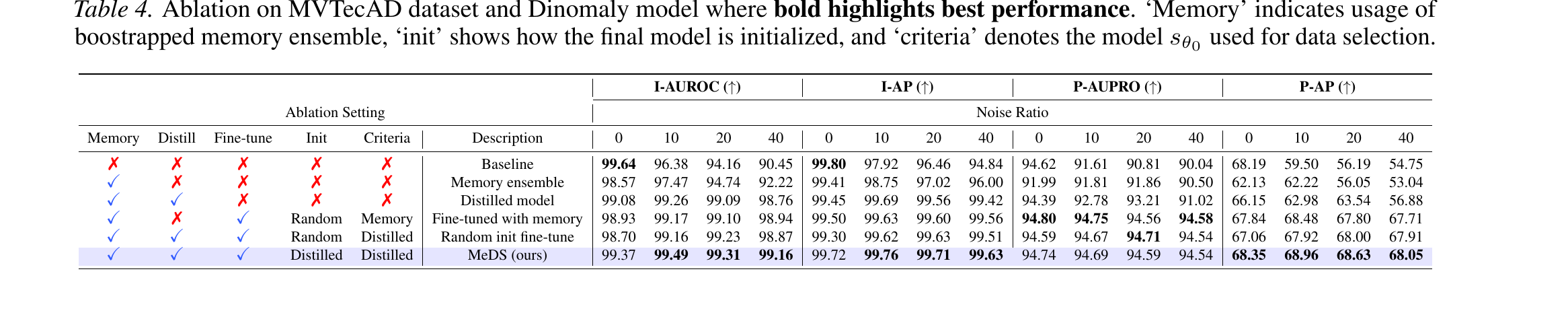
Component ablation (Table 4). Adding MeDS’s three stages one at a time, on top of a Dinomaly backbone, shows that each is necessary. Reading the table top to bottom — from the bare baseline to the full method — the metrics improve at every step, and the gains are largest under heavy noise:
- The bootstrapped memory ensemble alone sharply improves image-level robustness under noise (e.g. I-AUROC at \(40\%\) noise jumps from \(90.45 \to 92.22\)), but its pixel-level localization stays limited — it relies on frozen features.
- Distillation transfers that coarse robustness into a trainable network and refines its features, giving consistent gains across all metrics.
- Progressive fine-tuning improves both levels further, with the largest jump on the pixel-level P-AP metric (up to \(68.05\) at \(40\%\) noise) — precise segmentation without overfitting to the contaminated samples.
The last rows isolate the fine-tuning design and confirm both halves matter: using the distilled model for both initialization (“init”) and sample selection (“criteria”) beats using the raw memory ensemble or a randomly-initialized model.
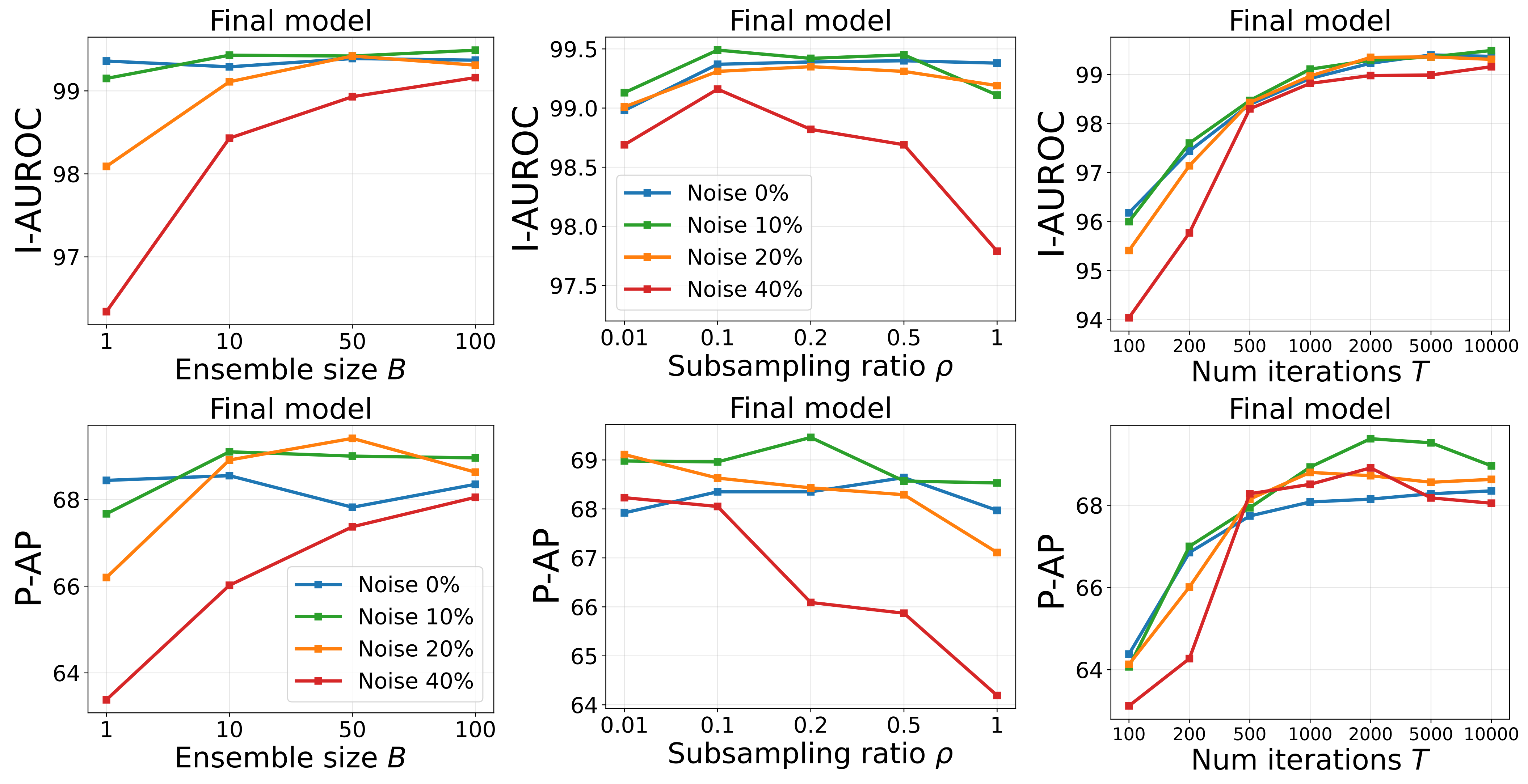
Robustness to hyperparameters. A big reason MeDS needs no noise-ratio-specific tuning is that it is insensitive to most of its hyperparameters, and a single fixed subsampling ratio works across every noise level. The figure below sweeps the final model’s image-level AUROC (top row) and pixel-level P-AP (bottom row) against three hyperparameters, with a separate curve per noise ratio (\(0/10/20/40\%\)):
- Ensemble size \(B\) (left). Both metrics climb steeply from a single memory and flatten by \(B \approx 50\); larger ensembles mainly stabilize the high-noise curves (the \(40\%\) case gains the most). We use \(B = 100\), comfortably inside the saturated region.
- Subsampling ratio \(\rho\) (middle). There is a clear peak around \(\rho = 0.1\): too small wastes data, while too large lets anomalous features leak into the memory and erodes the normal–anomaly gap — most damaging at \(40\%\) noise. Crucially, the same \(\rho = 0.1\) is best at every noise level, which is exactly why no per-noise tuning is needed (and matches the sweet spot predicted by Theorem 1).
- Distillation iterations \(T\) (right). Performance rises and then plateaus instead of degrading. This is the payoff of progressive selection: where the distilled-only model of Step 2 would start overfitting to noise, fine-tuning on the self-selected clean subset lets the model train far longer safely — so the exact stopping point no longer matters.
Active Label Correction
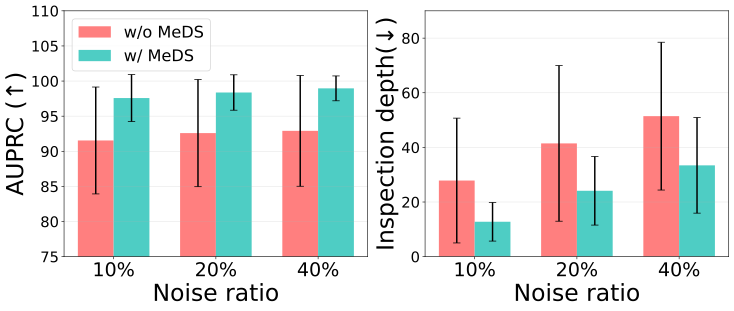
Beyond fully-automatic detection, MeDS doubles as a tool for cleaning datasets. By ranking training images from most- to least-suspicious (using its selection scores), it lets a human reviewer find and remove contaminated samples while inspecting far fewer images — instead of checking every single one. Concretely, MeDS pushes contaminated samples higher up the list (better ranking quality, measured by AUPRC) and shrinks the inspection depth — the fraction of the data you must review to catch all the contamination — cutting annotation effort across every noise level.